成长之路.1
成长之路.1
1.计算机组成
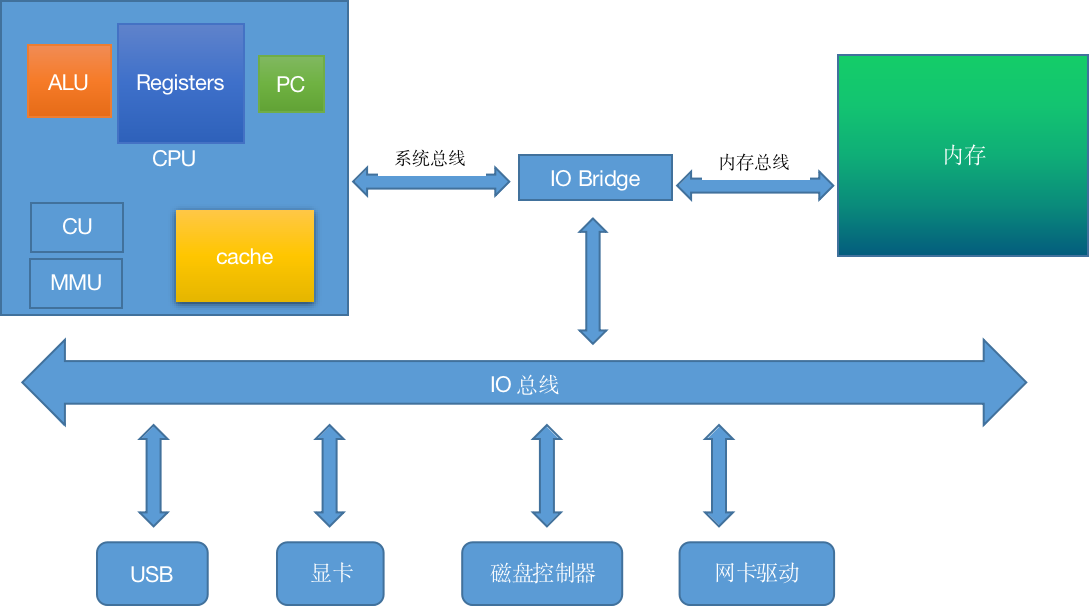
- ALU:数学逻辑单元,用来做计算
- Registers:寄存器,用来做存储
- PC:程序计数器,用来存储指令
2.进程与线程
一个程序,读入内存,全是0和1构成
从内存读入到CPU计算,这个时候要通过总线
怎么区分一段01的数据到底是数据还是指令?
总线分为3种:控制总线,地址线,数据线
一个程序的执行,首先把可执行文件放到内存,找到起始(main)的地址,逐步读出指令和数据,进行计算并写回内存
什么是进程?什么是线程
- 进程:一个程序进入内存,分配内存空间,被称之为进程,是静态概念,同时产生一个主线程
- 线程:一个进程内部,有多个任务并发的需求,共享进程空间但不共享计算,,是动态概念
一个ALU只能执行一个线程!
超线程:一个ALU对应多个PC|Registers,所谓的4核8线程
3.线程的切换
保存上下文,保存线程现场
- 问题:是不是线程数量越多,执行效率越高?
线程切换浪费时间,浪费资源
- 问题:单核CPU多线程执行有没有意义?
有,减少线程等待的资源浪费
- 问题:对于一个程序,设置多少个线程合适?(线程池设定多少核心线程?)
理论
:是处理器的核的数目,可通过Runtime.getRuntime().availableProcessors()得到
:是期望CPU的利用率(介于0-1之间)
W/C:等待时间与计算时间的比率
实际当中先结合公式预估,然后通过压测确定
4.CPU并发控制
4.1缓存一致性协议
CPU的速度和内存的速度(100:1)
这里的速度指的是ALU访问寄存器的速度比访问内存的速度快100倍
为了充分利用CPU的计算能力,在CPU和内存中间引入了缓存的概念
现在的工业实践,多采用3级缓存的架构
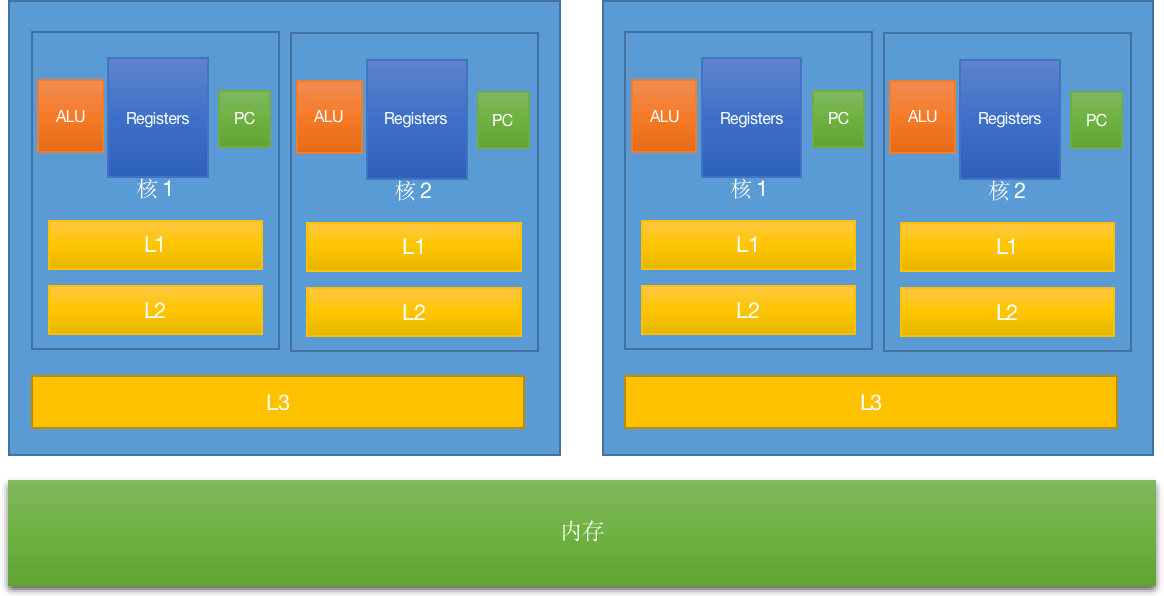
缓存行:一次性读取的数据块(从内存到缓存到寄存器)数据大小64byte(64 * 8bit)
缓存行大命中率高,读取效率低,缓存行小命中率低读取效率高
缓存一致性协议:由于缓存行的存在,我们必须有一种机制,来保证缓存数据的一致性,这种机制被称为缓存一只性协议
4.2关中断
4.3系统屏障
CPU乱序执行
为什么会乱序执行?主要是为了提高效率
调整执行位置
在等待费时的指令的时候,优先执行后面的指令
- cpu读取从内存中读取数据到寄存器,用时100个时间单位
- cpu执行寄存器中某个数据+1,用时1个时间单位
可以先执行2,在执行1
as-if-serial
单个线程,两条语句,未必是按照顺序执行
单线程的重排序,必须保证
as-if-serial:看上去像是序列化(单线程)
双端检索机制(DCL-double check lock)安全吗?
public class SingletonDemo {
private volatile static SingletonDemo instance = null;
private SingletonDemo() {
System.out.println(Thread.currentThread().getName() + " 进入构造器");
}
public static SingletonDemo getInstance() {
if (instance == null) {
synchronized (SingletonDemo.class) {
if (instance == null) {
instance = new SingletonDemo();
}
}
}
return instance;
}
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
SingletonDemo.getInstance();
}, String.valueOf(i)).start();
}
}
}
DCL 机制不一定线程安全,原因是有指令重排序的存在,加入 volatile 可以禁止指令 重排,原因在于某一个线程执行到第一次检测,读取到的 instance 不为 null 时,instance 的对象可能没有完成初始化
instance = new SingletonDemo();可以分为一下三部分
- memory = allocate();//分配内存空间 (new出来)
- instance(memory);//初始化对象 (调用构造方法)
- instance = memory;设置 instance 指向刚分配的内存地址,此时 instance!=null (建立指向关系)
步骤 2 和步骤 3 不存在数据依赖关系,可能存在指令重排序
this溢出问题(不要在构造方法中启动线程)
警告
不要在构造方法中启动线程
import java.io.IOException;
public class Test {
private int num = 8;
public Test() {
new Thread(() -> {
System.out.println(this.num);
}, "a").start();
}
public static void main(String[] args) throws IOException {
new Test();
System.in.read();
}
}
禁止指令乱序执行
- cpu级别禁止指令重排序
- 编译器级别实现了禁止编译器重排序
- JVM级别禁止指令重排序(最终落实到CPU级别)
JVM内存屏障
volicate 底层C++实现其实是lock命令
inline void OrderAccess::fence(){
if(os::is_MP()){
#ifdef AMD64
_asm_ volatile("lock; addl $0,0(%%rsp)":::"cc","memory")
#else
_asm_ volatile("lock; addl $0,0(%%esp)":::"cc","memory")
#endif
}
}
相关信息
LOCK用于在多处理器中执行命令时对共享内存的独占使用
它的作用是能够将当前处理器对应的缓存内容刷新到内存,并使其他的处理器对应的缓存失效
另外还提供了有序的指令无法越过这个内存屏障的作用
4.4总线/缓存锁
5.AQS
抽象同步队列:AbstractQueuedSynchronizer解决数据安全问题
什么是数据安全问题?
数据安全问题的原因是什么?(资源竞争---多线程)
小李子🌰
public class Test {
// 共享资源
private static Integer num = 0;
// 操作
public static void incr() {
try {
// 为了查看效果
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
num++;// 原子性问题
}
public static void main(String[] args) throws InterruptedException {
CountDownLatch c = new CountDownLatch(1000);
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
incr();
c.countDown();
}, "" + i).start();
}
c.await();
System.out.println("num: " + num);
}
}
造成数据安全的原因?
- 可见性
- JMM[内存模型]volatile,synchronized,Lock
- 有序性
- 指令优化volatile,synchronized,Lock
- 原子性
- AtomicInteger,synchronized,Lock
public class Test {
// 共享资源
private static Integer num = 0;
private static Lock lock = new ReentrantLock();
// 操作
public static void incr() {
lock.lock();
try {
// 为了查看效果
Thread.sleep(1);
num++;// 原子性问题
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
CountDownLatch c = new CountDownLatch(1000);
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
incr();
c.countDown();
}, "" + i).start();
}
c.await();
System.out.println("num: " + num);
}
}
5.1Lock
自己实现一🦐
lock做了什么操作
- 排他性,互斥型
/**
* 自己🦐
* 约定state=0表示锁空闲
* state>0表示锁被占用
*/
int state = 0;
if(state==0){
state++;//注意原子性⚠️
}else{
wait();
}
AbstractQueuedSynchronizer
/**
* The synchronization state.
*/
private volatile int state;
- 存储没有抢占到锁的线程
数组、集合、链表、队列....
提示
源码中通过双向链表存储
addWaiter()
enq()
- 阻塞掉没有抢占到锁的线程
wait();
LockSupport.park();
提示
源码中通过parkAndCheckInterrupt阻塞线程
unlock做了什么操作
- 释放锁
state--
- 唤醒阻塞的线程
notify/notifyAll
LockSupport.unpark()
5.2ReentrantLock源码分析(lock方法)
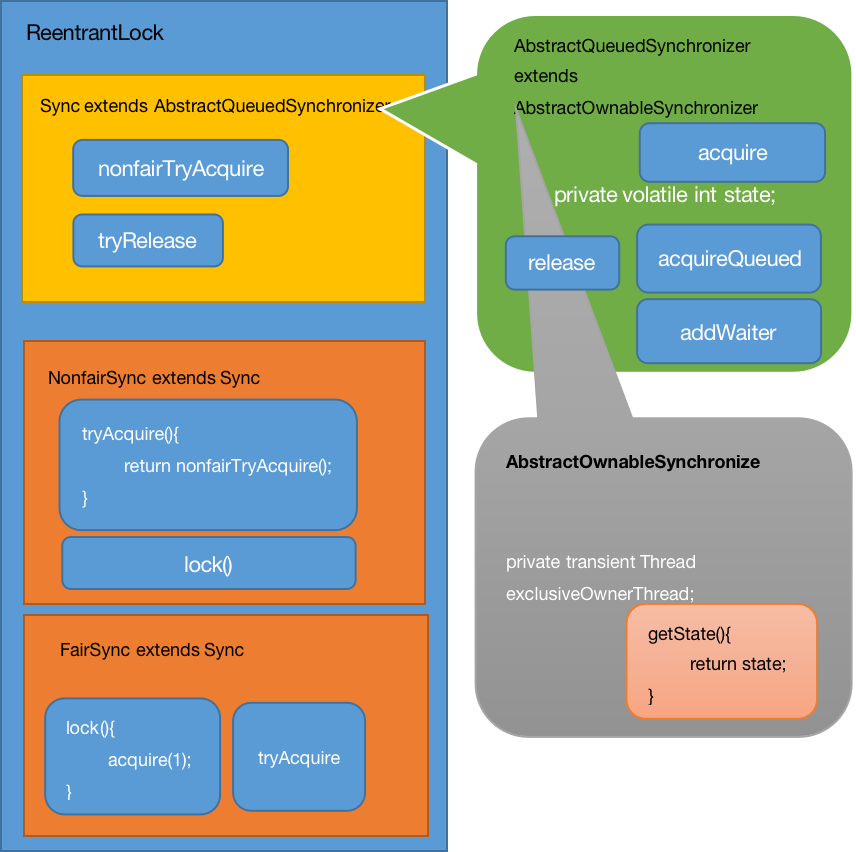
构造器
new对象时调用的是非公平的同步器
private static Lock lock = new ReentrantLock();
//属性,实现所有同步机制的同步器
private final Sync sync;
//构造器
public ReentrantLock() {
sync = new NonfairSync();
}
非公平锁
调用lock方法时,调用的是内部类NonfairSync中的lock方法
lock.lock();
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
/**
* Performs lock. Try immediate barge, backing up to normal
* acquire on failure.
*/
final void lock() {
//非公平首先试图获取锁
if (compareAndSetState(0, 1))
//赋予当前线程对象给实体AbstractOwnableSynchronizer类的属性exclusiveOwnerThread
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
公平锁
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
//公平锁重写了父类Sync的tryAcquire方法
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
父类Sync
abstract static class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = -5179523762034025860L;
/**
* Performs {@link Lock#lock}. The main reason for subclassing
* is to allow fast path for nonfair version.
*/
abstract void lock();
/**
* Performs non-fair tryLock. tryAcquire is implemented in
* subclasses, but both need nonfair try for trylock method.
*/
final boolean nonfairTryAcquire(int acquires) {
//1. 获取当前的线程对象
final Thread current = Thread.currentThread();
//2. 获取当前的锁的状态值
int c = getState();
if (c == 0) {
//再次判断
if (compareAndSetState(0, acquires)) {
//修改🔒的状态值
setExclusiveOwnerThread(current);
return true;
}
}//锁的拥有者就是当前线程(重入)
else if (current == getExclusiveOwnerThread()) {
//锁状态值+1
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
//如果当前线程不是锁的拥有对像,抛出异常
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
//c!=0表示重入
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
protected final boolean isHeldExclusively() {
// While we must in general read state before owner,
// we don't need to do so to check if current thread is owner
return getExclusiveOwnerThread() == Thread.currentThread();
}
final ConditionObject newCondition() {
return new ConditionObject();
}
// Methods relayed from outer class
final Thread getOwner() {
return getState() == 0 ? null : getExclusiveOwnerThread();
}
final int getHoldCount() {
return isHeldExclusively() ? getState() : 0;
}
final boolean isLocked() {
return getState() != 0;
}
/**
* Reconstitutes the instance from a stream (that is, deserializes it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
setState(0); // reset to unlocked state
}
}
acquire
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
//多于2个线程
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
//第二个线程
enq(node);
return node;
}
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
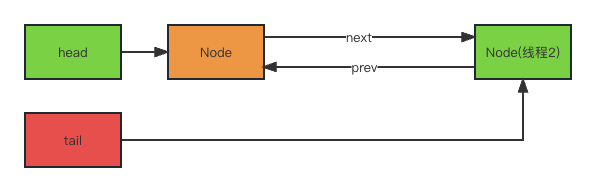
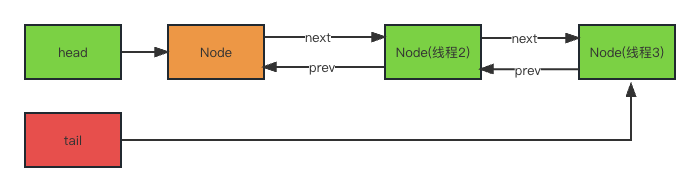
acquireQueued
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
//如果当前节点的上一节点是head节点那么先去试图获取锁
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
//阻塞
//shouldParkAfterFailedAcquire维护了节点的排队状态,将节点等待状态改为-1
//parkAndCheckInterrupt中断线程
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
private final boolean parkAndCheckInterrupt() {
//阻塞
LockSupport.park(this);
return Thread.interrupted();
}
private void setHead(Node node) {
head = node;
node.thread = null;
node.prev = null;
}
5.3ReentrantLock源码分析(unlock方法)
public void unlock() {
sync.release(1);
}
public final boolean release(int arg) {
//尝试释放锁
if (tryRelease(arg)) {
//释放成功
Node h = head;
if (h != null && h.waitStatus != 0)
//去唤醒阻塞队列中的节点,将首节点的等待状态置为0.并且判断next是否等待超时
unparkSuccessor(h);
return true;
}
return false;
}
5.4衍生
微服务多系统情况下,采用分布式锁原理互通
提示
- 排他性,互斥型
- 存储没有抢占到锁的线程
- 阻塞掉没有抢占到锁的线程
- 释放锁
- 唤醒阻塞的线程
6.JVM
简单概念
垃圾回收算法(三种)
- Mark-Sweep:标记清除
- Copying:拷贝(复制)
- Mark-Compact:标记整理
6.1垃圾回收模型
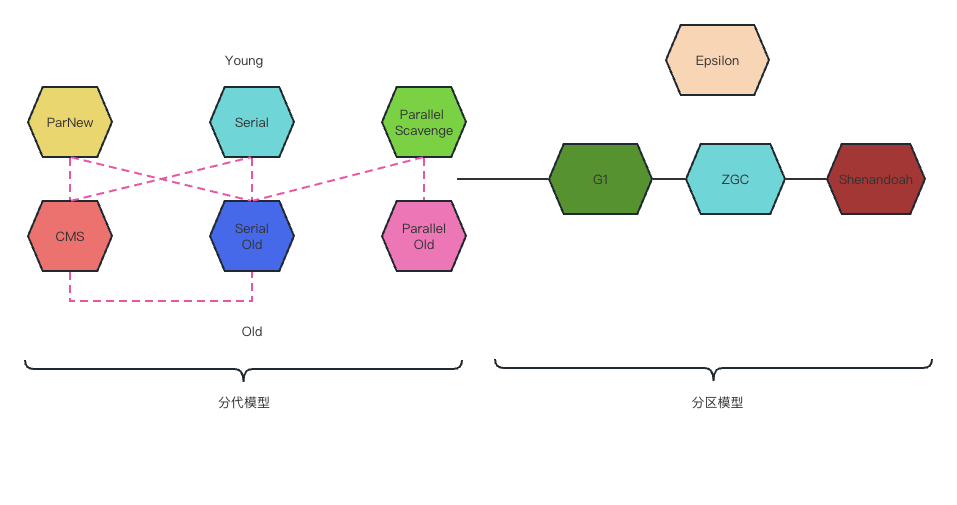
Serial
a stop-the-world(STW/卡顿),copying collector which uses a single GC thread
Parallel Scavenge
a stop-the-world,copying collector which multiple GC threads
1.8默认 ps/po
1.9以后默认G1
CMS
concurrent mark sweep
a mostly concurrent,low-pause collector.
4 phases
- initial mark(初始标记,找到根节点,STW)
- concurrent mark(并发标记,三色标记算法标记节点)
- remark(重新标记STW)
- concurrent sweep(并发清理)
三色标记算法
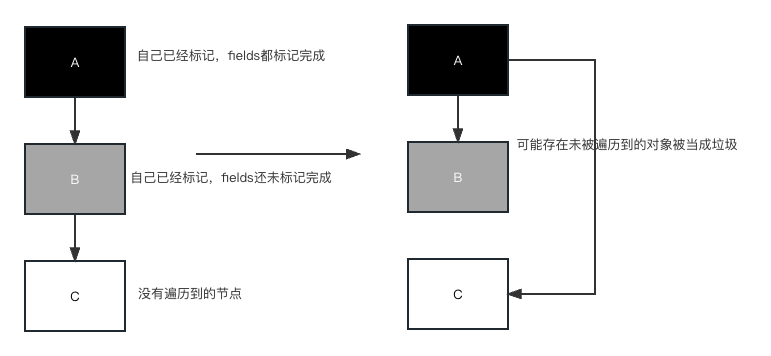
CMS解决三色标记过程中的漏标方案
Incremental Update
通过写屏障JVM在A.x = C的(后面加上A.color = grey)时候,如果A是黑色,C是白色,标A为灰
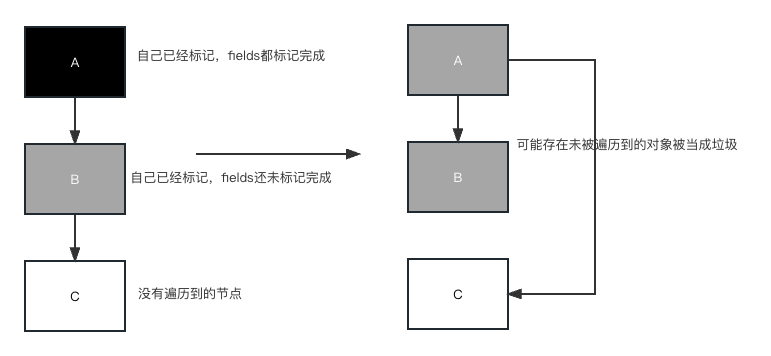
上面还存在漏标的可能,如果对象A有两个属性
- m1(垃圾回收线程),正在标记A,已经标记完属性1,正要标记属性2
- m2(业务逻辑线程),把属性1指向白色对象C
- m1(垃圾回收线程),标记完属性2,认为所有属性均已标记完,把A设为黑色,结果C漏标
为了解决C漏标问题,所以会remark
G1
依然采用三色标记算法
解决三色标记过程中的漏标方案
SATB:Snapshot At the Begining
在起始的时候做一个快照 当B->C消失时,要把这个引用推到GC的堆栈记录下来,保证D还能被扫描到,配合RSet,只用扫描哪些Region引用到D这个Region了
垃圾回收器和内存大小的关系
- Serial 几十兆
- PS上百兆-几个G
- CMS 20G
- G1 上百G
- ZGC 4T-16T(JDK13)--
6.2GC常用参数
- -Xmn年轻代 -Xms最小堆 -Xmx最大堆 -Xss栈空间
- -XX:+UseTLAB,使用TLAB默认打开
- -XX:+PrintTLAB,打印TLAB的使用情况
- -XX:TLABSize,设置TLAB大小
- -XX:+DisableExplictGC,System.gc()不用管,FGC
- -XX:+PrintGC
- -XX:+PrintGCDetail
- -XX:+PrintHeapAtGC
- -XX:+PrintGCTimeStamps
- -XX:+PrintVMOptions
- -XX:+PrintFlagsFinal -XX:+PrintFlagsInitial,必须会用
- -Xloggc:opt/log/gc.log
- -XX:MaxTenuringThreshold,省代年龄,最大值15
Parallel常用参数
- -XX:SuvivorRedio
- -XX:PreTenureSizeThreshold
- -XX:MaxTenuringThreshold,大对象到底多大
- -XX:ParallelGCThreads,并行收集器线程数,同样适用于CMS,一般设为与CPU核数相同
- -XX:+UseAdaptiveSizePolicy,自动选择各区比例大小
CMS常用参数
- -XX:+UseConcmarkSweepGC
- -XX:+ParallelCMSThreads,CMS线程数量
- -XX:CMSInitiatingOccupancyFraction,使用多少比例的老年代后开始CMS收集,默认是68%,如果频繁发生SerialOld卡顿,应该调小,频繁CMS回收
- -XX:+UseCMSCompactAtFullCollection,在FGC时进行压缩
- -XX:CMSFullGCsBeforeCompaction,多少次FGC后进行压缩
- -XX:+CMSClassUnloadingEnabled
- -XX:CMSInitiatingPermOccupancyFraction,达到什么比例时进行Prem回收
- GCTimeRadio,设置GC时间占用程序运行时间的百分比
- -XX:MaxGCPauseMillis,停顿时间,GC会尝试各种手段来达到这个时间
G1常用参数
- -XX:UseG1GC
- -XX:MaxGCPauseMillis,建议值,G1会尝试调整young区块数来达到这个值
- -XX:GCPauseIntervalMillis,GC的时间间隔时间
- -XX:G1HeapRegionSize,分区大小
- -XX:G1NewSizePercent,新生代比例大小,默认5%
- -XX:G1MaxNewSizePercent,新生代最大比例大小,默认60%
- —XX:GCTimeRedio,GC时间建议比例,G1会根据时间调整堆空间
- ConcGCThreads,线程数量
- InitiatingheapOccupancyPercent,启动G1的堆空间占用比例
6.3Root Searching
GC roots
- 线程栈变量
- 静态变量
- 常量池
- JNI指针