内存溢出处理
内存溢出处理
1. 查看内存占用情况定位线程
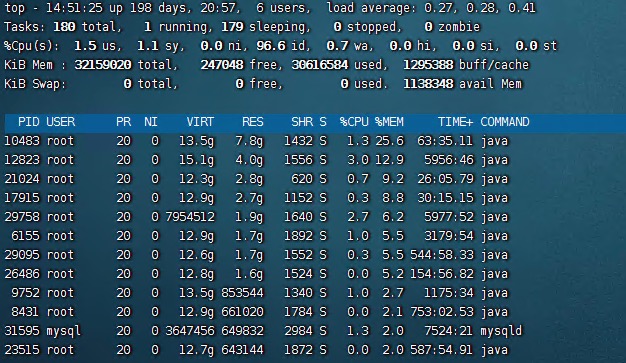
使用top命令进行查看,由于要查看内存使用情况所以需要按内存排一下序
#按进程的CPU使用率排序
运行top命令后,键入大写P
#按进程的内存使用率排序
运行top命令后,键入大写M
2. 定位线程问题(通过命令查看线程情况)
ps p 10483 -L -o pcpu,pmem,pid,tid,time,tname,cmd
从这个可以看到线程情况,当时情况紧急没有截图,所以我下面的图是同一个服务写文档时运行的
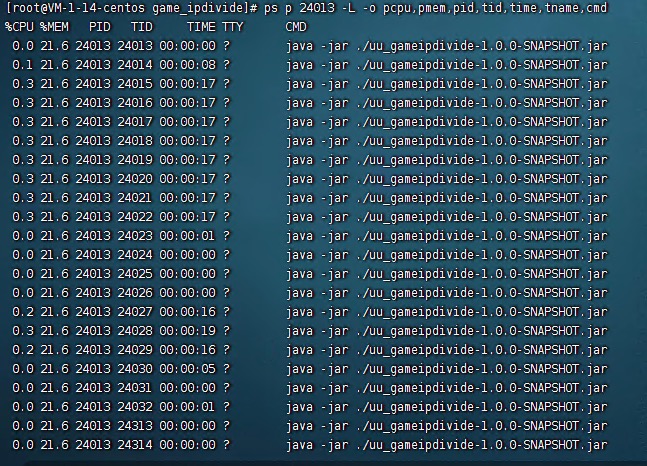
具体可以执行下面操作看有多少个线程
ps p 24013 -L -o pcpu,pmem,pid,tid,time,tname,cmd |wc -l
100
3. 查看内存使用堆栈
在这里我挑选了TID=24014的线程进行分析(选择一个执行时间较长的),首先需要将24014这个id转换为16进制。需输入如下命令
printf "%x\n" 24014
5dce
4. 将PID为 24013 的堆栈信息打印到jstack.log中
#输出目录自定
jstack -l 24013 > /usr/local/temp/jstack.log
查看具体信息后,发现程序中并没有自己写的代码有死锁或者是等待的东西,那就应该是默认配置相关了,其中有两个比较多http-nio-xxxx-exec-xx和lettuce-eventExecutorLoop-1-x
http-nio-4001-exec-30是Tomcat的工作线程名称。在Tomcat中,每个工作线程都被分配一个独特的名称,以便在调试和性能分析时能够轻松地跟踪线程的执行情况。
http-nio-4001-exec-30 中的 4001 表示Tomcat监听的端口号, exec 表示该线程是Tomcat的工作线程, 30 表示该线程的标识符。
如果在jstack输出中看到大量类似 http-nio-xxxx-exec-xx 的线程,这可能意味着应用程序正在处理大量的并发请求。每个请求都需要一个工作线程来处理,并且这些工作线程都需要占用一定的内存和CPU资源。如果应用程序的并发请求量过高,可能会导致系统资源瓶颈,进而影响应用程序的性能和稳定性。
如果应用程序需要处理大量的并发请求,建议根据实际情况来配置Tomcat的线程池参数,以确保应用程序的性能和稳定性。
这边使用的是springboot2.3X以上的版本,配置内置的tomcat参数与之前的有些不一样
在application.yml中进行配置,例如:
server:
tomcat:
threads:
max: 500 //线程池的最大线程数。默认值200
min-spare: 50 //线程池中最少的空闲线程数。默认值10
idle-timeout: 60000 //指定在空闲线程被回收之前等待的最大毫秒数。默认值60s
accept-count: 200 //指定在队列中等待处理的最大连接数。默认值100
max-connections: 20000 //最大连接数。默认值10000
lettuce-eventExecutorLoop-1-x 是Lettuce Redis客户端的线程名称,其中的 x 表示线程标识符。Lettuce使用Netty作为底层网络通信框架,每个Netty EventLoop都会创建一个Lettuce线程,并分配一个独特的线程名称,以便在调试和性能分析时能够轻松地跟踪线程的执行情况。
在Lettuce Redis客户端中,每个Redis命令都是异步执行的,即客户端会在发送请求之后立即返回,并通过回调函数或者Future等方式获取结果。Lettuce使用EventLoop线程来处理I/O事件、连接管理和Redis命令执行等任务,以提高客户端的性能和吞吐量。
如果在jstack输出中看到大量类似 lettuce-eventExecutorLoop-1-x 的线程,这可能意味着应用程序正在与Redis进行大量的交互,并且使用了Lettuce客户端。每个Lettuce线程都需要占用一定的内存和CPU资源,如果线程数量过多,可能会导致系统资源瓶颈,进而影响应用程序的性能和稳定性。
如果应用程序需要与Redis进行大量的交互,建议根据实际情况来配置Lettuce的线程池参数,以确保应用程序的性能和稳定性。
在application.yml中进行配置,例如:
spring:
redis:
host: localhost # Redis服务器地址,默认为localhost
port: 6379 # Redis服务器端口,默认为6379
password: # Redis密码,默认为空
database: 0 # Redis数据库索引(0-15),默认为0
timeout: 1000 # 连接超时时间(毫秒),默认为1000
jedis:
pool:
max-active: 8 # 连接池最大连接数,默认为8
max-idle: 8 # 连接池最大空闲连接数,默认为8
min-idle: 0 # 连接池最小空闲连接数,默认为0
max-wait: -1 # 连接池最大等待时间(毫秒),默认为-1(表示无限等待)
修改了配置文件在观察吧,我在导出jstack的时候运维已经重启了服务,我不清楚这个是不是当时有问题的原因,但是从后来分析的情况来看,确实存在一定的问题...
后续会跟进...
后续跟进 : 我在执行ps p 10483 -L -o pcpu,pmem,pid,tid,time,tname,cmd命令式发现有个线程时间2分钟还没结束,去jstack查看了一下,是 System Clock
这个线程是一个系统线程,是JVM中专门负责管理系统时钟的线程,它会定期更新JVM中的系统时间,以及JVM中的一些相关参数,如 java.util.Date 和 System.currentTimeMillis()等方法的返回值。该线程的状态为 TIMED_WAITING ,意味着它是在等待时钟时间的到来,并在等待的过程中处于定时等待状态。这种状态在Java应用程序中非常常见,并且通常是正常的行为,不应该引起太多的注意。但是2分钟还没执行完就多少有点时间长,查看了一下代码,发现使用了 SimpleDateFormat
SimpleDateFormat 并不是线程安全的,如果多个线程同时使用同一个 SimpleDateFormat 对象进行日期格式化,就有可能出现线程安全问题,在程序中我也看到不知怎么的这一块是写在属性当中,所有方法共用,这一块应该存在问题,优化到方法内部或者如果确定要只定义一个的话:
如果多个线程同时读取同一个SimpleDateFormat对象的话,会出现线程安全问题,因为SimpleDateFormat不是线程安全的。所以如果多个线程同时读取时可能会出现线程阻塞的情况。为了避免这种情况,可以考虑使用ThreadLocal来保证每个线程有自己的SimpleDateFormat对象。这样就可以避免多个线程之间的竞争,提高程序的性能和稳定性。
5. 补充1
后续跟进中,发现内存还是越来越大,使用top以后res还是居高不下,接着进行查看跟踪
根据进程id执行
查看活着的进程
## 查看活着的进程
jmap -histo:live pid
## 这里截取了部分
num #instances #bytes class name
----------------------------------------------
1: 80790 10028800 [C
2: 8588 5616312 [B
3: 84228 2695296 java.util.concurrent.ConcurrentHashMap$Node
4: 26168 2302784 java.lang.reflect.Method
5: 80161 1923864 java.lang.String
6: 15826 1748536 java.lang.Class
7: 27455 1317840 org.aspectj.weaver.reflect.ShadowMatchImpl
...
2808: 1 32 io.lettuce.core.resource.ExponentialDelay
2809: 1 32 io.netty.buffer.EmptyByteBuf
2810: 1 32 io.netty.channel.DefaultChannelId
2811: 1 32 io.netty.channel.nio.NioEventLoopGroup
2812: 1 32 io.netty.util.AttributeKey
2813: 1 32 io.netty.util.HashedWheelTimer$Worker
2814: 1 32 io.netty.util.concurrent.DefaultEventExecutorGroup
2815: 1 32 io.netty.util.concurrent.DefaultPromise$StacklessCancellationException
2816: 2 32 io.netty.util.concurrent.MultithreadEventExecutorGroup$1
2817: 2 32 io.netty.util.concurrent.ThreadPerTaskExecutor
2818: 2 32 io.netty.util.internal.logging.Slf4JLoggerFactory
2819: 1 32 java.beans.ThreadGroupContext
2820: 1 32 java.beans.ThreadGroupContext$1
2821: 1 32 java.io.FileNotFoundException
2822: 1 32 java.io.RandomAccessFile
2823: 1 32 java.io.UnixFileSystem
2824: 1 32 java.lang.ArithmeticException
2825: 1 32 java.lang.ArrayIndexOutOfBoundsException
2826: 1 32 java.lang.ClassCastException
2827: 1 32 java.lang.IllegalStateException
2828: 1 32 java.lang.NullPointerException
2829: 2 32 java.lang.Shutdown$Lock
2830: 1 32 java.lang.StackTraceElement
提示
此命令可以用来查看内存信息,实例个数以及占用内存大小
- num:序号
- instances:实例数量
- bytes:占用空间大小
- class name:类名称,[C is a char[],[S is a short[],[I is a int[],[B is a byte[],[[I is a int[][]
查看fullGC以后剩下的都是一些系统之类的内存占用,暂时看起来正常?🐶
查看占用内存多的线程
jmap -histo pid|head -20
查看堆内存使用情况
然后我又看了一下堆内存使用情况
jmap -heap pid
Debugger attached successfully.
Server compiler detected.
JVM version is 25.231-b11
using thread-local object allocation.
Parallel GC with 8 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 8233418752 (7852.0MB)
NewSize = 171966464 (164.0MB)
MaxNewSize = 2744123392 (2617.0MB)
OldSize = 343932928 (328.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 975699968 (930.5MB)
used = 41373880 (39.45720672607422MB)
free = 934326088 (891.0427932739258MB)
4.240430599255692% used
From Space:
capacity = 857735168 (818.0MB)
used = 1616864 (1.541961669921875MB)
free = 856118304 (816.4580383300781MB)
0.18850387162859109% used
To Space:
capacity = 858783744 (819.0MB)
used = 0 (0.0MB)
free = 858783744 (819.0MB)
0.0% used
PS Old Generation
capacity = 2798649344 (2669.0MB)
used = 40148408 (38.28850555419922MB)
free = 2758500936 (2630.711494445801MB)
1.4345637150318178% used
31252 interned Strings occupying 3290976 bytes.
程序没有做jvm配置,使用的是默认属性,但是GC过后看起来使用率什么的都很低,暂时看起来也正常,但是top的res还是在7G左右
查看进程内存映射文件
jmap -dump:format=b,file=heap.bin pid
这将生成一个名为 heap.bin 的二进制文件,其中包含了 Java 堆的内存快照。
使用内存分析工具:使用内存分析工具,如 Eclipse Memory Analyzer (MAT) 或 VisualVM 的 Heap Dump Analyzer,打开生成的 heap.bin 文件
我使用的是JProfiler分析快照文件,好像也还好,
查看进程的内存映像信息
pmap -x pid
这个命令用于查看进程的内存映像信息,能够查看进程在哪些地方用了多少内存。常用 pmap -x pid 来查看。
有两处的address都在3G以上,可能这就是问题所在...待解决
警告
待使用GDB进一步分析占用大量匿名内存的进程
通过使用GDB,可以进一步分析占用大量内存的进程,并查看具体内存地址周围的内容。这有助于定位内存占用问题的根本原因,并进一步调试和优化代码。
请注意,使用GDB进行调试需要一定的调试经验,并且在生产环境中进行调试时需要格外小心。确保了解GDB的使用方法,并对正在调试的进程进行适当的备份和保护。
堆外/其他内存占用
这边怀疑是堆外内存占用或者其他类型的内存占用
堆外内存使用:堆外内存是指由Java程序直接分配的、不在Java堆中的内存。这种内存通常用于存储直接字节缓冲区、本地方法栈、JNI(Java Native Interface)调用等。您可以使用Java虚拟机的工具和API来监视和诊断堆外内存的使用情况。例如,可以使用jcmd pid VM.native_memory summary命令来查看Java进程的堆外内存摘要。
本地资源占用:Java程序可能会使用一些本地资源,如文件句柄、网络连接、数据库连接等,这些资源可能会占用系统的内存或文件描述符。可以检查程序中是否有没有正确关闭或释放这些本地资源的情况,确保它们被正确地管理和释放。
第三方库或组件:您的程序可能使用了一些第三方库或组件,这些库可能使用了堆外内存或本地资源。请查阅这些库的文档,了解它们是否有堆外内存的使用要求或注意事项。
操作系统级的内存占用:除了Java进程本身,操作系统也会使用一定的内存。例如,操作系统缓存、共享库等都会占用一部分内存。您可以使用操作系统的工具或命令来监视系统级的内存占用情况。
综上所述,如果怀疑存在堆外内存的占用或其他类型的内存占用,建议使用适当的工具和方法来监视和分析堆外内存、本地资源的使用情况,并进一步检查第三方库或组件的文档,确保程序中没有未释放的资源或异常的内存占用情况。
注意
NMT 是一项Java虚拟机(JVM)功能,它允许监视和诊断Java进程使用的堆外内存。
可以根据需要启用 Native Memory Tracking(NMT)来跟踪堆外内存的使用情况
-XX:NativeMemoryTracking=summary
请注意,启用 NMT 可能会增加对系统资源的使用,包括内存和处理器资源。因此,在启用 NMT 时,请确保系统具备足够的资源来支持您的应用程序和监控需求。
启用 NMT 后,您可以使用以下命令来查看堆外内存的摘要信息:
jcmd pid VM.native_memory summary
这边开启了NMT在观察一段时间....
暂时改动
- 开启了NMT(其中一台服务)
- 在分析问题的时候,突然出现了一个大的对象直接进入老年代,优化代码
这边在分析问题的时候,发现刚完成GC后出现了一个很大的对象出现在了老年代区域,是由于对象太大年轻代无法分配足够的内存空间,所以直接进入了老年代,查看代码是有一处查询数据库,由于有个字段前端传过来为空了,这边之前没做处理,直接查询数据库导致数据超量,完成代码优化,后续持续观察...
6. 跟进
通过持续观察,目前程序占用内存一只良好,应该没什么问题了,不过在笔者的学习过程中,发现了一个比较好用的线上监控诊断的产品,阿里的Arthas,可以更好的协助定位问题
非常强大...Σ(●゚д゚●)